Docker Guide
Includes Setting Up Docker Swarm with 3 Nodes.
- Getting Started with Docker & Docker Engine
- Storage
- Networking in Docker Engine
- Docker-Compose
- Docker Hub
- Swarm Mode
Getting Started with Docker & Docker Engine
What is Dockerengine?
 Overview
Overview
Docker Engine is the heart of Docker, a technology that allows you to create and run small, lightweight packages called containers. These containers are like tiny virtual machines but much more efficient. They contain everything an application needs to run, including the code, system libraries, and settings, so it behaves the same on any computer.
Docker 101
Docker Engine consists of the following major components:
- Docker Daemon: This is the background service that handles container management on a Docker host. It listens for Docker API requests and manages the lifecycle of Docker containers, including starting, stopping, and monitoring.
- REST API: This API allows external tools and programs to communicate with the Docker Daemon, making it possible to manage Docker resources programmatically.
- Docker CLI: The Command-Line Interface (CLI) provides users with the ability to interact with the Docker Daemon using commands. It allows for creating and managing containers, images, networks, and volumes from the terminal.
Docker Engine can run on any Linux-based operating system, including distributions like Debian, Ubuntu, and CentOS, as well as other systems like Windows and macOS using platform-specific adaptations. On Linux systems, Docker containers share the host's kernel, making them lightweight and highly efficient.
How Does Docker Engine Work?
At its core, Docker Engine uses a client-server model. You, the user, interact with Docker by typing commands (using the CLI) or through other software (via the REST API). The Docker Daemon (the server part) listens to these requests and manages all the containers on your system.
-
Images and Containers: Containers are created from something called images. Think of an image as a template or blueprint for a container. When you run an image, it becomes a container that can actually perform tasks.
-
Layers and File System: Docker Engine makes things more efficient by building containers in layers, where each layer represents a change or addition to the image. This way, Docker doesn’t need to rebuild everything from scratch each time you make changes.
-
Isolation and Resources: Docker Engine uses special features in the Linux kernel (the core of the operating system) to isolate containers from each other, ensuring that one container’s actions don’t affect another. It also controls how much CPU, memory, and other resources each container can use.
Key Features of Docker Engine
-
Lightweight: Containers don’t need their own operating system; they use the host system’s resources. This makes them much smaller and faster than virtual machines.
-
Portability: Once you create a container, it will run the same way on any system that has Docker, no matter where it is. This makes it easy to move your application from your computer to a cloud server or any other environment.
-
Fast: Containers start up almost instantly because they don’t have to load a whole operating system. This makes them ideal for quick testing and development.
-
Isolation: Each container has its own environment, meaning that your application and its dependencies won’t interfere with other applications on the same system.
More Capabilities of Docker Engine
-
Networking: Docker Engine allows containers to communicate with each other and the outside world through networks. You can connect containers together or expose them to the internet easily.
-
Storage: Docker Engine can manage data that needs to persist even when containers are restarted or deleted. It does this using volumes (for storing data outside of containers) or bind mounts (which link folders on the host system to containers).
-
Orchestration Support: For larger applications, Docker Engine works well with tools like Docker Swarm and Kubernetes. These tools help manage and automate the running of many containers at once, often across multiple servers.
Interested on More?
Check Out "Docker Vs VM's"
Docker vs. VM
 Overview
Overview
In this article, we'll break down the differences between Docker and Virtual Machines (VMs), providing insights to help you decide which technology might be the better fit for your needs. Both Docker and VMs are essential tools for running applications, but they serve different purposes. Before diving into the comparison, let’s start with a brief explanation of each.
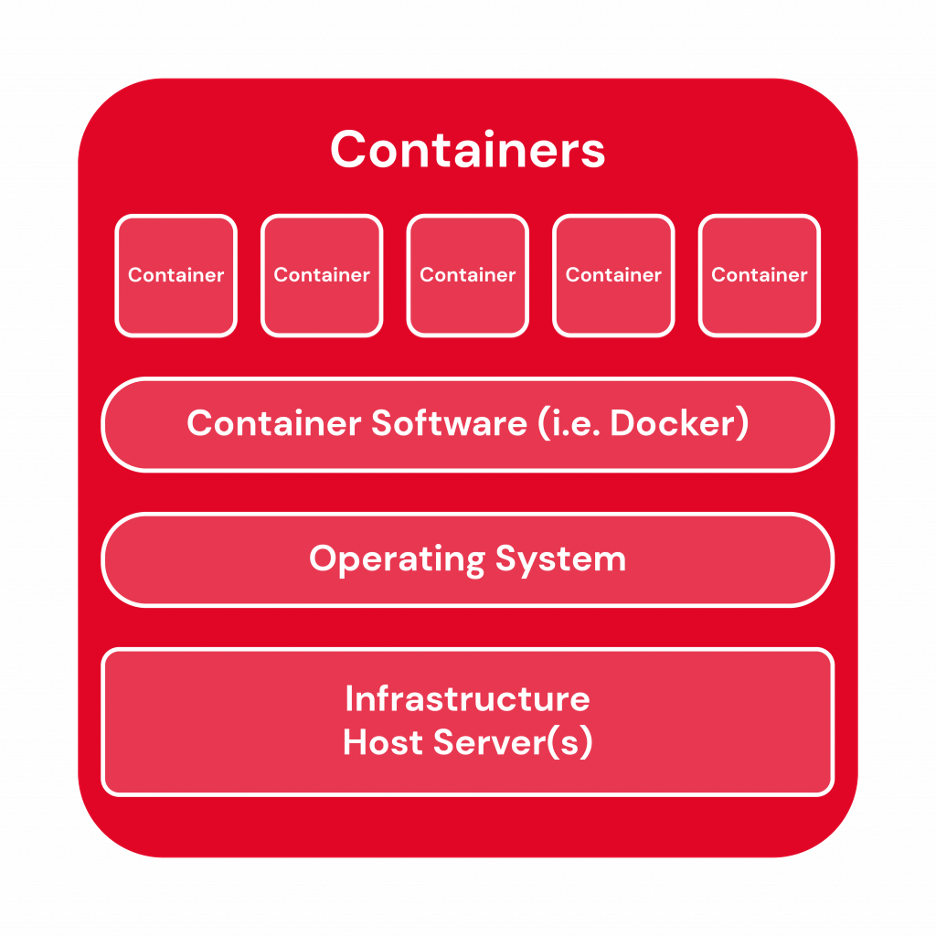
What is Docker?
In today's rapidly evolving tech world, organizations aim to digitize their businesses, but often face challenges with managing diverse applications across cloud and on-premises infrastructure. Docker addresses this challenge by providing a container platform that can host traditional applications and modern microservices, running on both Linux and Windows.
Docker is a tool and a form of virtualization technology that simplifies the development, deployment, and management of applications. It achieves this by using containers, which are lightweight, self-contained packages that bundle everything needed to run an application, such as libraries, dependencies, and configuration files.
With Docker, applications run consistently across different systems because the container includes all the necessary elements. Containers are lightweight since they don’t need a separate operating system like virtual machines do. Instead, Docker containers share the host system’s OS kernel, making them faster and more efficient.
Key benefits of containers include:
- Reduced IT management overhead
- Smaller snapshots of applications
- Faster startup times
- Easier security updates
- Simplified code migration and deployment
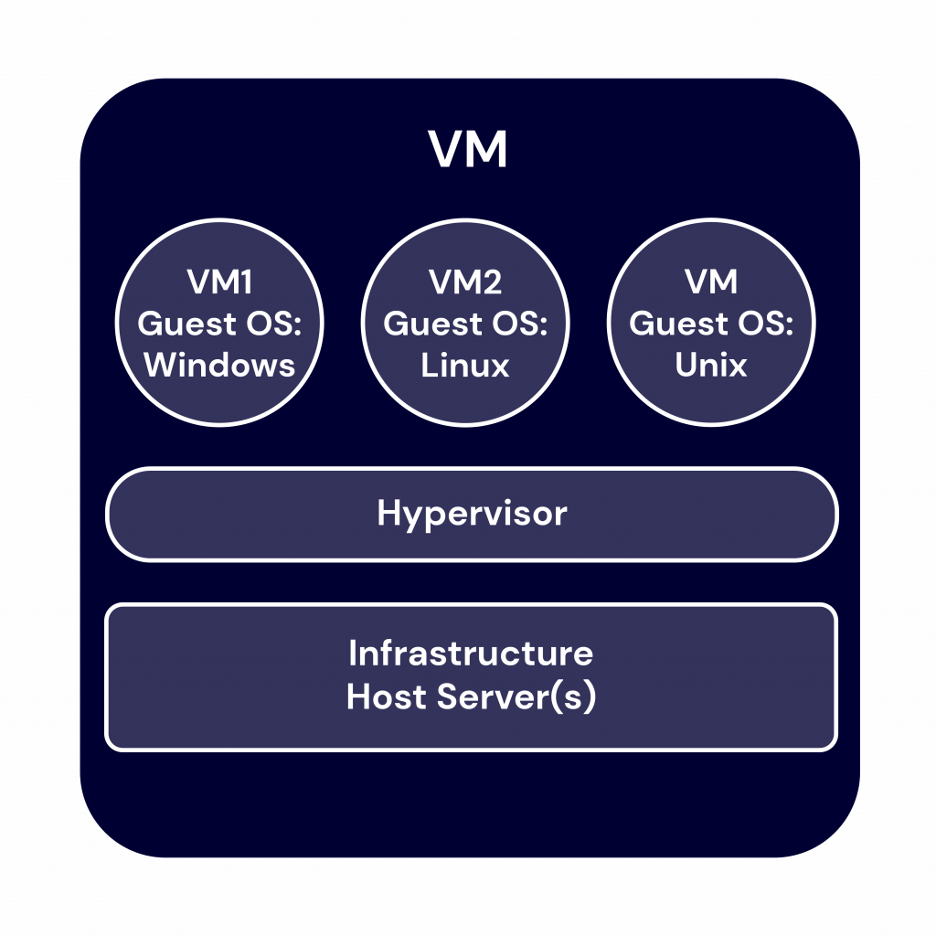
What is a Virtual Machine (VM)?
A Virtual Machine (VM), on the other hand, is a technology that allows a single physical machine to run multiple independent operating systems, each with its own resources. VMs are typically used when performing tasks that might be risky for the host system, such as running potentially harmful software or testing new operating systems. VMs offer strong isolation, so any issues inside a VM won't affect the host system.
Each VM is a complete system with its own operating system, virtual hardware, and resources like CPU, memory, and storage. A physical host can run multiple VMs, allowing for different environments to run simultaneously. VMs are commonly used in server virtualization, where a physical server is divided into several VMs to optimize hardware utilization.
There are two types of VMs:
- System Virtual Machines: Allow multiple VMs to run their own operating systems and share the physical resources of the host. These are typically managed by a hypervisor.
- Process Virtual Machines: Provide a platform-independent environment for running applications, hiding the underlying hardware details from the application.
While VMs provide strong isolation, they can consume a lot of resources since each VM includes its own operating system. This leads to longer boot times and higher resource usage compared to containers.

Docker vs Virtual Machines: Key Differences
Now that you know what Docker and VMs are, let's explore the key differences:
1. Architecture
-
Virtual Machines (VMs): VMs require both a host operating system and a guest operating system for each virtual machine. This guest OS could be any OS (e.g., Linux or Windows), regardless of what the host OS is. Each VM includes a complete instance of the operating system, which makes it resource-intensive.
-
Docker: Docker containers, on the other hand, run on a single host OS and share that OS’s kernel. Because of this, containers are much more lightweight, starting faster and using fewer system resources. Docker is ideal for running multiple applications on a single OS kernel.
2. Security
-
Virtual Machines (VMs): VMs are more secure by design because they run fully isolated from one another. Each VM has its own OS, kernel, and security features. For applications that require heightened security and isolation, VMs are generally the better choice.
-
Docker: While Docker containers also offer isolation, they share the host’s kernel, which can pose security risks. Running a compromised container with root access could potentially lead to an attack on the host system. It’s important to apply additional security measures when using Docker containers in sensitive environments.
3. Portability
-
Virtual Machines (VMs): VMs are somewhat portable, but moving them between different environments (especially with different hardware) can introduce compatibility issues. VMs are ideal for static applications that don’t need to be moved often.
-
Docker: Docker containers are extremely portable and can run consistently on any system with Docker installed. Since they don’t require a guest OS, they can be easily transferred between different platforms and environments (development, testing, production), ensuring seamless portability.
4. Performance
-
Virtual Machines (VMs): VMs require more system resources because each VM must load its own operating system. This leads to longer boot times and higher resource consumption for memory, CPU, and storage.
-
Docker: Docker containers are lightweight, allowing them to start and stop quickly with minimal overhead. Since containers share the host OS kernel, they use fewer resources, which leads to better performance and faster scaling.
5. Resource Efficiency
-
Virtual Machines (VMs): VMs need more system resources as they load an entire OS for each instance. Running multiple VMs can quickly consume a large portion of the host’s CPU, memory, and storage, making them less efficient when compared to Docker containers.
-
Docker: Docker containers don’t need a full OS, which makes them highly efficient in terms of memory and CPU usage. Since containers share resources based on demand, they are well-suited for applications that need to scale quickly
Docker vs Virtual Machine Comparison Table
| Feature | Docker | Virtual Machines (VMs) |
|---|---|---|
| Boot Time | Starts in seconds | Takes minutes to boot |
| Architecture | Shares host OS kernel | Each VM has its own guest OS |
| Memory Efficiency | Lightweight, no need to virtualize | Requires full OS for each VM |
| Isolation | Limited isolation, shares host OS | Full OS isolation |
| Deployment | Quick and easy deployment | Slower and more resource-intensive |
| Usage | Best for containerized apps | Better for full OS and high security |
Should You Choose Docker or Virtual Machines?
Choosing between Docker and VMs depends on your use case:
-
When to use Docker: If you need to quickly develop, test, and deploy applications, Docker is a great choice. Containers are portable, lightweight, and work well with modern development workflows like microservices and CI/CD pipelines. Docker is also ideal for running applications across different environments without worrying about compatibility issues.
-
When to use Virtual Machines (VMs): For applications that require full OS isolation, increased security, or the ability to run multiple operating systems on the same host, VMs are the better option. VMs are commonly used in production environments, especially when security is a primary concern, or when running legacy applications that require a specific operating system.
Conclusion: Complementary Tools
Docker and virtual machines are not competing technologies, but rather complementary tools that serve different purposes. VMs provide strong isolation and are ideal for running applications that need their own OS, while Docker containers are lightweight, flexible, and designed for quickly deploying modern applications. Many organizations use both Docker and VMs in a hybrid approach, depending on the specific needs of their applications and infrastructure.
Both technologies have their strengths, and understanding the differences will help you make the right choice for your project.
Install Docker Engine on Debian
This Wikipage hase been integrated by aeoneros from the Original Source: Docker.Docks
To get started with Docker Engine on Debian, make sure you meet the prerequisites, and then follow the installation steps.
Prerequisites
OS requirements
OS Requirements
To install Docker Engine, you need the 64-bit version of one of these Debian versions:
- Debian Bookworm 12 (stable)
- Debian Bullseye 11 (oldstable)
Docker Engine for Debian is compatible with x86_64 (or amd64), armhf, arm64, and ppc64le (ppc64el) architectures.
Uninstall old versions
Uninstall Old Versions
fore you can install Docker Engine, you need to uninstall any conflicting packages.
Distro maintainers provide unofficial distributions of Docker packages in their repositories. You must uninstall these packages before you can install the official version of Docker Engine.
The unofficial packages to uninstall are:
docker.iodocker-composedocker-docpodman-docker
Moreover, Docker Engine depends on containerd and runc. Docker Engine bundles these dependencies as one bundle: containerd.io. If you have installed the containerd or runc previously, uninstall them to avoid conflicts with the versions bundled with Docker Engine.
Run the following command to uninstall all conflicting packages:
for pkg in docker.io docker-doc docker-compose podman-docker containerd runc; do sudo apt-get remove $pkg; doneapt-get might report that you have none of these packages installed.
Images, containers, volumes, and networks stored in /var/lib/docker/ aren't automatically removed when you uninstall Docker. If you want to start with a clean installation, and prefer to clean up any existing data, read the uninstall Docker Engine section.
Installation for Linux
Before you install Docker Engine for the first time on a new host machine, you need to set up the Docker apt repository. Afterward, you can install and update Docker from the repository.
1. Set up Docker's apt repository
# Add Docker's official GPG key:
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/debian/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
# Add the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/debian \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get updateIf you use a derivative distro, such as Kali Linux, you may need to substitute the part of this command that's expected to print the version codename:$(. /etc/os-release && echo "$VERSION_CODENAME")
Replace this part with the codename of the corresponding Debian release, such as bookworm.
2. Install the Docker packages
To install the latest version, run:
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin3. Verify that the installation is successful by running the hello-world image:
sudo docker run hello-worldThis command downloads a test image and runs it in a container. When the container runs, it prints a confirmation message and exits.
You have now successfully installed and started Docker Engine.
Storage
Bind mounts (persistant data into Container)
Bind Mounts
When you use a bind mount, a file or directory on the host machine is mounted from the host into a container. By contrast, when you use a volume, a new directory is created within Docker's storage directory on the host machine, and Docker manages that directory's contents.
When to Use Bind Mounts
Bind mounts are appropriate for the following types of use cases:
- Sharing source code or build artifacts between a development environment on the Docker host and a container.
- Creating or generating files in a container and persisting them onto the host's filesystem.
- Sharing configuration files from the host machine to containers, such as how Docker provides DNS resolution by mounting
/etc/resolv.conffrom the host machine into each container. - Bind mounts can also be used for builds: you can bind mount source code from the host into the build container to test, lint, or compile a project.
Bind-Mounting Over Existing Data
If you bind mount a file or directory into a directory in the container in which files or directories exist, the pre-existing files are obscured by the mount. Once the mount is removed, the files become visible again.
With containers, there's no straightforward way of removing a mount to reveal the obscured files again. Your best option is to recreate the container without the mount.
Considerations and Constraints
- Bind mounts have write access to files on the host by default. Use the
readonlyorrooption to make the bind mount read-only. - Bind mounts are tied to the Docker daemon host, not the client.
- If using Docker Desktop, the daemon runs inside a Linux VM, with mechanisms to handle bind mounts transparently.
- Bind mounts rely on the host machine's filesystem structure. Containers may fail if run on a different host without the same directory structure.
Syntax
To create a bind mount, you can use either the --mount or --volume flag:
docker run --mount type=bind,src=<host-path>,dst=<container-path>
docker run --volume <host-path>:<container-path>The --mount flag is generally preferred as it is more explicit and supports all available options.
Syntax for Docker Compose
volumes:
- /path/to/your/hostpath:/path/inside/the/container:roSee more about binding mounts on the Official Docker Docs.
Networking in Docker Engine
Overview - How does Docker Networks work?
Container networking refers to the ability for containers to connect to and communicate with each other, or to non-Docker workloads.
Containers have networking enabled by default, and they can make outgoing connections. A container has no information about what kind of network it's attached to, or whether its peers are also Docker workloads or not. A container only sees a network interface with an IP address, a gateway, a routing table, DNS services, and other networking details. That is, unless the container uses the none network driver.
This page describes networking from the point of view of the container, and the concepts around container networking. It doesn’t cover OS-specific details about how Docker networks work. For more information about how Docker manipulates iptables rules on Linux, see Packet filtering and firewalls.
User-Defined Networks
You can create custom, user-defined networks and connect multiple containers to the same network. Once connected, containers can communicate with each other using container IP addresses or container names.
docker network create -d bridge my-net
docker run --network=my-net -itd --name=container3 busybox
Drivers
The following network drivers are available by default and provide core networking functionality:
| Driver | Description |
|---|---|
bridge |
The default network driver. |
host |
Removes network isolation between the container and the Docker host. |
none |
Completely isolates a container from the host and other containers. |
overlay |
Connects multiple Docker daemons together. |
ipvlan |
Provides full control over IPv4 and IPv6 addressing. |
macvlan |
Assigns a MAC address to a container. |
For more information, take a deepdive into the different Drivers at this Post.
Container Networks
In addition to user-defined networks, you can attach a container to another container's networking stack directly using the --network container:<name|id> flag format.
The following example demonstrates running a Redis container with Redis binding to localhost, then running the redis-cli command and connecting to the Redis server:
docker run -d --name redis example/redis --bind 127.0.0.1
docker run --rm -it --network container:redis example/redis-cli -h 127.0.0.1Published Ports
By default, containers on bridge networks don’t expose ports to the outside world. Use the --publish or -p flag to make a port available externally. Examples:
| Flag Value | Description |
|---|---|
-p 8080:80 |
Maps port 8080 on the Docker host to TCP port 80 in the container. |
-p 192.168.1.100:8080:80 |
Maps port 8080 on host IP 192.168.1.100 to TCP port 80 in the container. |
-p 8080:80/udp |
Maps UDP port 8080 on the host to UDP port 80 in the container. |
Important: Publishing container ports is insecure by default. To restrict access, bind ports to localhost or specific IP addresses.
IP Address and Hostname
Containers receive an IP address for every network they attach to. The Docker daemon dynamically assigns these IPs based on the network’s subnet. You can specify IP addresses manually using the --ip or --ip6 flags.
By default, a container’s hostname is its ID. You can override this using --hostname.
For additional network aliases, use the --alias flag when connecting a container to a network.
For more details, see the official documentation.
DNS Services
By default, containers inherit DNS settings from the host. You can override these settings using the following flags:
| Flag | Description |
|---|---|
--dns |
The IP address of a DNS server. |
--dns-search |
A DNS search domain for non-fully qualified hostnames. |
--dns-opt |
Key-value pairs for DNS options. |
For more details, see the official documentation.
Docker-Compose
Docker Compose Overview & Usecases
Overview
Docker Compose is a tool that simplifies the definition and management of multi-container applications. It allows developers to configure all the services their application requires (such as databases, APIs, web services, etc.) in a single YAML file. Using this file, Docker Compose can create and start all containers with a single command, significantly streamlining the workflow.
For more Information about Networking, Secrets etc. CLICK ME ->
Key Benefits of Docker Compose
- Simplified Control: Docker Compose centralizes the management of multi-container applications in one YAML file, which simplifies orchestration and coordination.
- Efficient Collaboration: The Compose file is easy to share, enabling collaboration across development and operations teams.
- Rapid Application Development: By caching the container configuration, Docker Compose speeds up environment changes, allowing developers to quickly restart services without needing to rebuild unchanged containers.
- Portability Across Environments: The use of environment variables in the Compose file enables easy customization for different environments.
- Active Community Support: Docker Compose benefits from an extensive community, providing a rich source of resources and troubleshooting support.
How Docker Compose Works
Docker Compose uses a YAML configuration file, commonly named compose.yaml or docker-compose.yaml, to define and manage your application's services. This file follows the Compose Specification, which formalizes how multi-container applications are defined.
The lifecycle of a Compose-defined application is managed through the Docker CLI (docker compose) and can be controlled with commands such as:
-
Start services:
docker compose up -
Stop and remove services:
docker compose down -
View logs:
docker compose logs -
List services and their statuses:
docker compose ps
Compose File Example
Below is a simplified example of a Docker Compose file that defines two services (a frontend web application and a backend database), persistent volumes, and network isolation.
services:
frontend:
image: example/webapp
ports:
- "443:8043"
networks:
- front-tier
- back-tier
configs:
- httpd-config
secrets:
- server-certificate
backend:
image: example/database
volumes:
- db-data:/etc/data
networks:
- back-tier
volumes:
db-data:
driver: flocker
driver_opts:
size: "10GiB"
configs:
httpd-config:
external: true
secrets:
server-certificate:
external: true
networks:
front-tier: {}
back-tier: {}
This configuration defines:
- Two services:
frontendandbackend. - Persistent data storage using a
db-datavolume. - A secret for the HTTPS certificate.
- Two isolated networks (
front-tierfor external access, andback-tierfor internal communication).
How Compose Manages Services
When running docker compose up, Docker Compose creates the necessary containers, volumes, and networks based on the configuration in the YAML file. It also injects any required secrets and configuration files. To check the state of your services, you can use:
docker compose psThis command provides information on the running services, their current status, and any exposed ports.
Conclusion
Docker Compose is an essential tool for developers and operations teams managing multi-container applications. Its YAML-based configuration, simplicity in controlling environments, and active community support make it an ideal choice for development, testing, and even single-host production deployments.
Docker Hub
What is Dockerhub? & Keyfeatures

Overview of Docker Hub
Docker Hub is the world's largest repository for container images, offering a platform for developers and organizations to find, share, and distribute Docker container images. It serves as a centralized hub for containerized applications, making it easier to manage, deploy, and collaborate on container-based projects.
Docker Hub is designed to simplify the distribution of containerized applications, providing access to a vast library of pre-built container images from various sources, including community developers, open-source projects, and independent software vendors (ISVs).
Key Features of Docker Hub:
-
Image Repository: Docker Hub hosts millions of Docker images, from community-contributed applications to official images from well-known projects and vendors. These images are used to create Docker containers, enabling developers to quickly deploy and scale their applications.
-
Official Images: Docker Hub provides a collection of official images—pre-vetted, trusted container images provided by organizations such as Ubuntu, MySQL, Nginx, and many others. These images are maintained by the official developers, ensuring reliability and security.
-
Private Repositories: In addition to public images, Docker Hub allows users to create private repositories where they can store and manage their own container images. Private repositories are essential for organizations that want to keep their projects secure and limit access to internal users.
-
Automated Builds: Docker Hub supports automated builds, which allow developers to connect their code repositories (e.g., GitHub or Bitbucket) to Docker Hub. When changes are pushed to the code repository, Docker Hub automatically builds a new container image. This is a powerful feature for CI/CD pipelines, ensuring that applications are containerized and ready for deployment with every code update.
-
Webhooks: Docker Hub provides webhooks to trigger actions when a new image is pushed to a repository. This can be used to notify systems or services when a new version of an image is available.
-
Image Tags: Docker Hub allows developers to tag specific versions of their images, enabling users to pull different versions of the same image. For example, you can specify whether you want the
latestimage or a specific version like1.0.0. -
Docker Content Trust: To ensure the security of container images, Docker Hub integrates Docker Content Trust (DCT), which provides digital signatures for container images. This helps users verify the authenticity and integrity of images before they are pulled and run.
Conclusion
Docker Hub is a critical part of the Docker ecosystem, providing a centralized platform for container image distribution. Whether you're a solo developer, part of an open-source project, or an enterprise team, Docker Hub simplifies the process of finding, sharing, and deploying containerized applications. With its vast repository of community and official images, private repositories, automated builds, and security features, Docker Hub is an indispensable tool for managing container-based workflows at any scale.
Swarm Mode
Swarm mode Overview & Key Concepts
Docker Swarm Mode is a feature within Docker that allows you to manage a cluster of Docker nodes (computers running Docker) as if they were a single machine. This is extremely useful for deploying applications that require multiple containers distributed across various servers. It provides built-in tools for clustering, service orchestration, load balancing, and scaling without needing extra software.
In simple terms, Swarm Mode turns a collection of computers running Docker into a "swarm," allowing you to manage services across these machines as though they were one system.
How Docker Swarm Mode Works
When you deploy an application to a swarm, here’s what happens:
- You define a service (e.g., a web server) that should run in the swarm.
- You tell Docker how many replicas (copies) of this service you want running at all times.
- Docker ensures that these replicas are distributed across the available nodes.
- If one node fails or a container crashes, Docker automatically adjusts to maintain the desired state.
Here’s an example: Let’s say you want to run a web application in a swarm with 5 replicas of a web server. Docker will create 5 containers and distribute them across the nodes in the swarm. If one node fails, Docker will automatically start new containers on other nodes to keep 5 web servers running.
Key Concepts in Docker Swarm Mode
1. Nodes
A node is any machine that is part of a Docker Swarm cluster. Nodes can either be manager nodes (which control the swarm) or worker nodes (which run containers). In a real-world production environment, nodes are often spread across multiple physical servers or cloud machines.
- Manager Node: Manages the cluster by keeping track of tasks and assigning them to workers. The manager also ensures that the desired number of containers are always running.
- Worker Node: Receives and executes tasks given by the manager. Workers run the containers but do not manage the swarm.
2. Services and Tasks
-
A service is a definition of what needs to be run in the swarm. When you create a service, you specify things like the container image to use and how many copies (replicas) of the service should run.
There are two types of services:
- Replicated Services: The swarm manager assigns a set number of replica tasks to run across the available nodes.
- Global Services: A task for this service runs on every node in the swarm.
-
A task is a unit of work, which includes running a Docker container. Each task is scheduled by the swarm manager to be executed on one of the worker nodes. Once a task is assigned to a node, it remains on that node until it completes or fails.
3. Load Balancing
Docker Swarm has built-in load balancing to distribute traffic between the different containers running on the swarm. When external users access a service, the traffic is routed to any node in the swarm, and that node forwards the request to the appropriate container running the service. Swarm uses ingress load balancing for external traffic and internal DNS-based load balancing for traffic within the swarm.
4. Desired State Reconciliation
One of the most important features of Docker Swarm is its ability to maintain the desired state. The manager nodes constantly monitor the swarm and automatically adjust the number of containers to match what you have defined. For example, if one of the worker nodes fails, the manager will ensure that new containers are created on other nodes to maintain the required number of replicas.
Docker Swarm Mode Features
-
Cluster Management: Swarm Mode provides built-in tools for managing a cluster of Docker nodes without needing additional software.
-
Declarative Service Model: You define what you want your application to look like (number of containers, network, resources) and Docker ensures it matches your specification.
-
Automatic Scaling: You can increase or decrease the number of service replicas at any time, and Docker will automatically adjust the cluster to match.
-
Rolling Updates: When you update your application, Docker can gradually roll out the update to your nodes. If something goes wrong, you can roll back to a previous version of the service.
-
Multi-Host Networking: Docker allows services to communicate across different nodes using an overlay network. This simplifies networking across nodes in different locations.
-
Service Discovery: Docker Swarm automatically assigns each service a DNS name, so containers can find and communicate with each other easily.
-
Security: Docker Swarm Mode is secure by default. All communications between nodes in the swarm are encrypted using TLS, and each node must authenticate itself to the others.
Swarm Mode vs. Standalone Containers
When running Docker in Swarm Mode, you can still use standalone containers alongside your swarm services. However, there are key differences between the two:
- Swarm Services: These are managed by the swarm manager and offer advanced features like scaling, load balancing, and automatic updates.
- Standalone Containers: These are not part of the swarm, and you manage them manually, just like regular Docker containers.
When to Use Docker Swarm Mode?
- Production Environments: Swarm Mode is ideal for managing containerized applications in production environments where you need high availability and automatic failover.
- Distributed Applications: If your application needs to run across multiple servers or cloud instances, Docker Swarm provides the tools to manage the cluster efficiently.
- Scaling: If you expect your application to scale, Swarm Mode lets you easily add or remove replicas of your services without downtime.
Conclusion
Docker Swarm Mode is a powerful feature for managing and orchestrating containerized applications across a cluster of machines. It simplifies complex tasks like scaling, load balancing, and maintaining application availability, all while being integrated directly into Docker Engine. With Docker Swarm, you can manage multiple Docker hosts as one, ensuring your applications are resilient, scalable, and easy to update.
How Nodes work
What are Roles?
A swarm is a group of Docker hosts (servers running Docker) that are connected and work together to run containerized applications. Each host can play one of two roles:
- Manager: A node that controls the swarm. It handles the cluster management tasks, such as assigning workloads (tasks) to worker nodes and maintaining the desired state of the services.
- Worker: A node that does the actual work by running containers. The worker nodes execute the tasks assigned by the manager.
Any Docker host in the swarm can be a manager, a worker, or even perform both roles.
Example: Creating a 3-Node Docker Swarm with All Manager Nodes
Let’s walk through an example where we set up a Docker Swarm with three nodes, all acting as manager nodes. This scenario is useful when you want high availability and fault tolerance in your cluster, meaning if one or two manager nodes fail, the remaining nodes can continue managing the swarm.
Why Make All Nodes Managers?
In a Docker Swarm, manager nodes are responsible for handling the cluster's state, scheduling tasks, and distributing containers to the worker nodes. By making all three nodes managers, you ensure that your swarm can tolerate failures of one or even two nodes and still function. This is known as high availability because the swarm can elect a new leader and continue operating without downtime.
If you haven't already, read through the Swarm mode overview and key concepts.
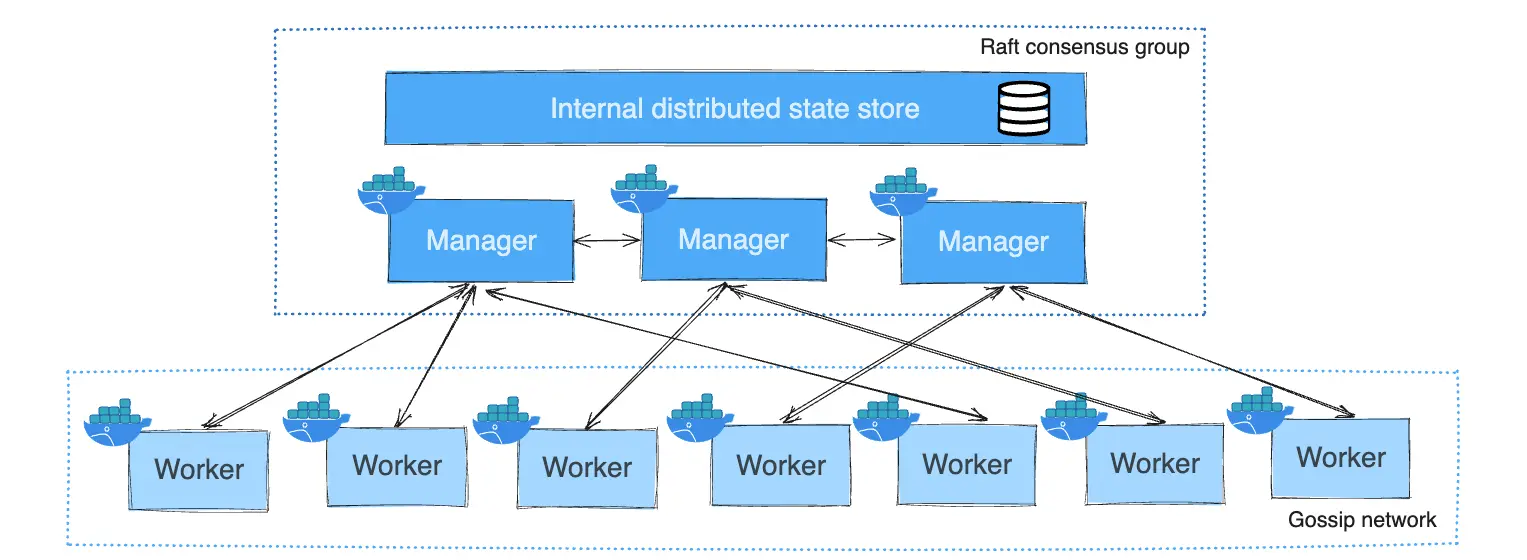
Manager Nodes
Manager nodes play a crucial role in maintaining and orchestrating the state of the swarm. They are responsible for:
- Maintaining Cluster State: Manager nodes keep track of the state of the swarm and all services running on it, ensuring that the desired state (e.g., the number of replicas of a service) is met.
- Scheduling Services: Managers are in charge of scheduling tasks (containers) across the worker nodes in the swarm.
- Serving Swarm Mode HTTP API Endpoints: Manager nodes expose the Swarm mode HTTP API, which is used to control the swarm via commands or automation.
Fault Tolerance and High Availability
Docker Swarm uses a Raft consensus algorithm to ensure that the state of the swarm is consistent across all manager nodes. This is particularly important for high availability. The general rule is that an odd number of managers provides fault tolerance, allowing the swarm to continue functioning if some managers fail.
- A three-manager swarm can tolerate the loss of one manager node.
- A five-manager swarm can tolerate the loss of two manager nodes.
The formula for fault tolerance is that a swarm can tolerate the loss of at most (N-1)/2 manager nodes, where N is the total number of managers.
Best Practices for Manager Nodes
- Odd Number of Managers: To take full advantage of Docker’s fault tolerance, always use an odd number of manager nodes. This ensures that the swarm can maintain quorum (i.e., the minimum number of nodes needed to keep the swarm functional).
- Limit the Number of Managers: Although adding more manager nodes increases fault tolerance, it does not improve performance or scalability. In fact, having too many manager nodes can slow down decision-making processes. Docker recommends a maximum of seven managers in a swarm.
Manager Node Failure
If you’re running a single-manager swarm and the manager node fails, the services on the worker nodes will continue to run, but you won’t be able to control or update the swarm. You’d need to recreate the swarm to recover full control.
In contrast, when running a swarm with multiple managers, if one manager fails, the remaining managers can take over, ensuring that the swarm continues to operate without downtime.
Worker Nodes
Worker nodes are simpler compared to manager nodes. Their primary purpose is to execute containers. Worker nodes don't participate in swarm management decisions and don’t maintain the state of the swarm.
- Executing Tasks: Workers run the containers assigned to them by the manager nodes. They receive tasks (containers to run) and report back to the managers on the status of these tasks.
- No Raft Participation: Worker nodes do not store the cluster's state and don’t participate in the Raft consensus. This allows them to focus purely on running workloads.
Worker Node Setup
In any Docker Swarm, there must be at least one manager node, but you can have any number of worker nodes. By default, all manager nodes also act as workers, meaning they can schedule tasks and run containers.
However, if you want to prevent managers from running containers (e.g., to dedicate them solely to management tasks), you can adjust their availability. This brings us to the concept of Drain Mode.
Manager Node Availability and Drain Mode
In a multi-node swarm, you may want to prevent managers from running any tasks or containers. For example, you might want to ensure that managers are purely dedicated to orchestration and scheduling tasks, leaving the heavy lifting of running containers to worker nodes.
You can change the availability of a manager node to Drain mode, which means the scheduler will not assign new tasks to that node, and existing tasks will be moved to other nodes.
To set a manager node to Drain mode, you can run the following command:
docker node update --availability drain <manager-node-name>This will ensure that the manager node doesn't run any new tasks but continues its role as a swarm manager, making scheduling decisions and maintaining the cluster's state.
Changing Roles: Promoting and Demoting Nodes
Swarm mode also provides flexibility when it comes to changing the roles of your nodes. You can promote a worker node to become a manager or demote a manager node to a worker if needed.
Promoting a Worker to a Manager
If you want to add more fault tolerance to your swarm or need to take a manager node offline for maintenance, you can promote a worker node to a manager. This is done with the following command:
docker node promote <worker-node-name>This is useful in situations where you want to ensure that the cluster remains highly available, even if one of your manager nodes needs to be taken down.
Demoting a Manager to a Worker
If you no longer need a manager node or want to reduce the number of managers for better performance, you can demote a manager back to a worker. This can be done using:
docker node demote <manager-node-name>Conclusion
Understanding the roles of manager and worker nodes in Docker Swarm is essential for creating a stable, highly available, and scalable cluster. Manager nodes handle critical tasks such as maintaining the cluster state and scheduling services, while worker nodes focus purely on running containers.
In larger clusters, having multiple manager nodes ensures that your swarm can tolerate failures without disrupting service. However, it’s important to maintain an odd number of managers for fault tolerance and to avoid adding too many managers, as this can slow down the swarm’s performance.
By effectively using Drain mode and node promotion/demotion, you can adjust your swarm’s architecture to meet your organization’s needs, ensuring optimal performance and availability.
How Services work
When Docker Engine operates in Swarm mode, services become the fundamental units for deploying and managing applications. A service is essentially a set of instructions for running containerized applications across multiple Docker nodes. This might be part of a larger application, such as a microservice architecture, or it could be a stand-alone service like an HTTP server or a database.
What is a Service?
A service in Docker Swarm represents a task that you want to run, such as running a containerized application.
When you create a service, you specify a few essential options:
- The container image to use for the service.
- Commands to execute inside the running containers.
- The port to expose to make the service available outside the swarm.
- An overlay network to connect the service with other services within the swarm.
- CPU and memory limits for the resources allocated to each service instance.
- Rolling update policies to control how services are updated across the swarm.
- The number of replicas (i.e., how many copies of the service) you want to run.
Services, Tasks, and Containers
Once you define the service, the swarm manager takes your service definition and turns it into one or more tasks. A task is the smallest unit of work in a swarm and represents a single instance of a container running on a node.
For example, if you want to balance traffic between three instances of a web server, you might deploy a service with three replicas. Each replica is a task, and each task runs one container on a different node.
- Service: Defines the application you want to run.
- Task: A unit of work managed by the swarm that runs a single container.
- Container: The actual application process that runs as part of a task on a node.
In short, when you deploy a service, you define the desired state, and Docker Swarm schedules that service across the available nodes.
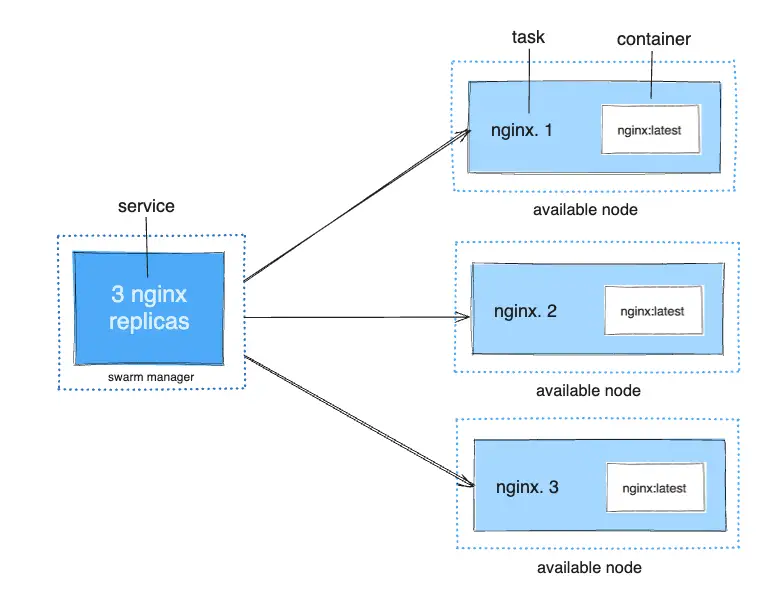
Tasks and Scheduling
When you create or update a service, you declare a desired state (e.g., three instances of an HTTP service). The orchestrator (which is part of the swarm manager) ensures that this state is met by creating and scheduling tasks. For instance, if you define a service with three replicas, the swarm manager creates three tasks. Each task runs a container on a node.
If a container crashes or fails its health check, the orchestrator detects the failure and schedules a new task to replace it, ensuring that the desired state of the service is always maintained.
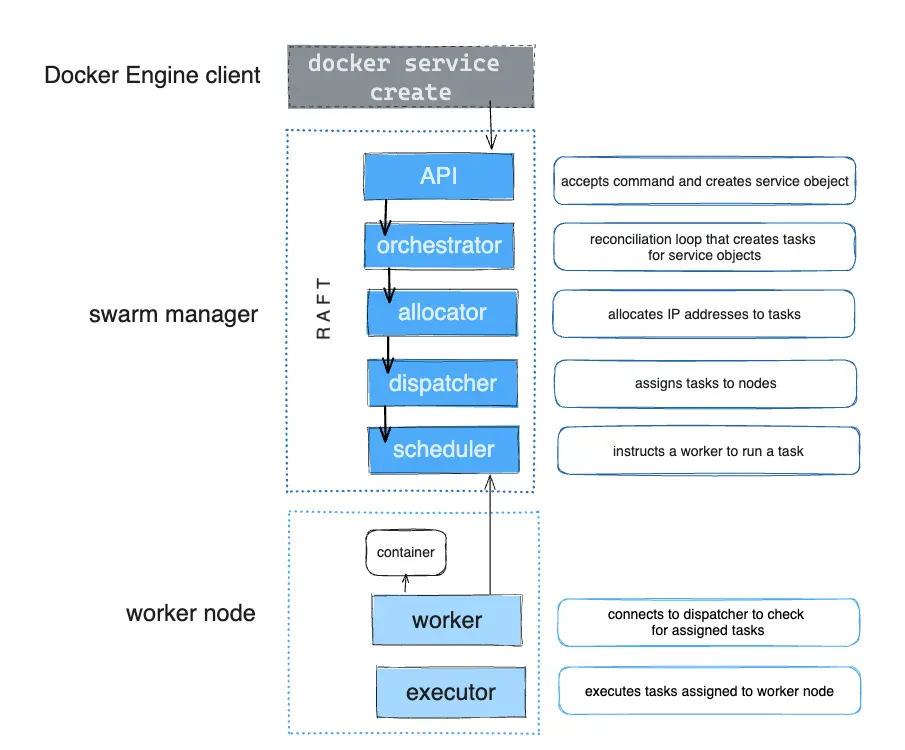
Pending Services
Sometimes, a service may remain in a pending state, meaning that it cannot be deployed yet. Here are a few scenarios where this might happen:
- Node Availability: If no nodes are available to run tasks (e.g., all nodes are in paused or drained mode), the service will remain in the pending state until nodes become available.
- Resource Constraints: If the service requires more memory or CPU than any node can provide (e.g., a service requiring 500GB of RAM but no node has that capacity), the service will stay pending.
- Placement Constraints: If the service is configured with specific placement constraints (e.g., to only run on certain nodes), it may stay pending until a suitable node is available.
Tip:
In these cases, it is often better to scale the service to zero replicas if your goal is to pause the service temporarily.
If your only intention is to prevent a service from being deployed, scale the service to 0 instead of trying to configure it in such a way that it remains in pending.
Replicated and Global Services
There are two types of services in Docker Swarm: replicated services and global services.
Replicated Services
For replicated services, you specify the number of identical tasks you want to run. Each replica runs on a separate node, providing redundancy and load balancing. For example, if you create a service with three replicas, the swarm manager ensures that three identical instances (tasks) of the service are running on different nodes.
This is useful for applications like web servers, where you want multiple instances of the same service to handle requests simultaneously.
Global Services
A global service runs one instance of the service on every node in the swarm. You do not specify the number of replicas; instead, the swarm ensures that each node runs exactly one instance of the service.
Global services are ideal for tasks like monitoring or logging agents, where you want each node to run the same service. For example, you might use a global service to run an anti-virus scanner or a network monitoring agent on every node in your swarm.
The diagram below shows a three-service replica in gray and a global service in black.
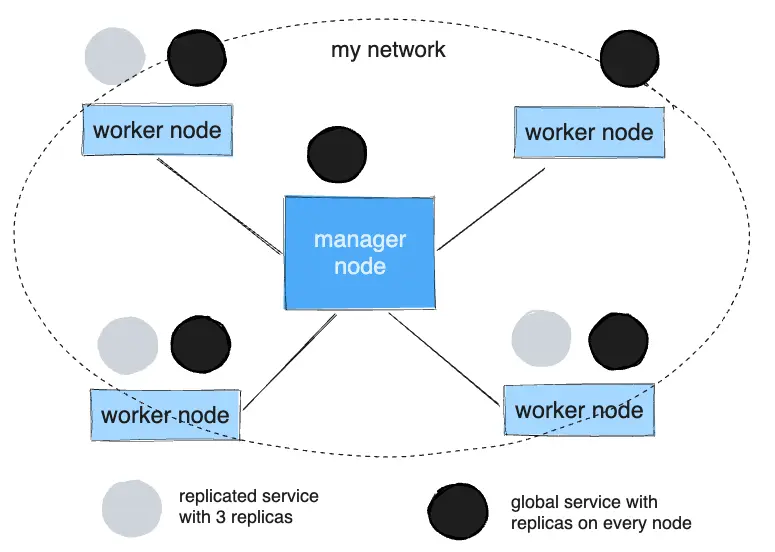
Getting started with Swarm mode & Create a swarm
This tutorial introduces Docker Swarm mode, which allows you to deploy and manage containerized applications across a cluster of Docker nodes. In Swarm mode, Docker Engine transforms multiple Docker hosts into a single, distributed system, making it easier to scale, orchestrate, and manage applications.
What This Tutorial Covers:
- Initializing a Docker Swarm
- Adding nodes to the Swarm
- Deploying services to the Swarm
- Managing the Swarm (Lightweight Version)
Prerequisites:
- You need three Linux hosts (physical or virtual machines) that can communicate over a network, with Docker installed.
- Open ports between the hosts.
- The IP address of the manager node.
Step 1: Setting Up the Environment
To get started, you'll need three Linux hosts that can communicate over a network. These hosts can be physical machines, virtual machines, or cloud instances (e.g., Amazon EC2).
- One of these hosts will be the manager (we’ll call it
manager1). - The other two hosts will be workers (
worker1andworker2).
You can follow most steps of this tutorial on a single-node Swarm (with just one host), but for full multi-node functionality, you’ll need three hosts.
Install Docker Engine on Linux Hosts
Follow Docker's official installation instructions for your Linux distribution to install Docker on each of your machines. Once Docker is installed, you’re ready to create your Swarm.
Check the Manager Node's IP Address
You’ll need the IP address of the manager node (manager1) for the Swarm to function properly. To find it, run the following command on manager1:
ifconfigThis will display a list of available network interfaces. Pick the IP address that is accessible to the other nodes in the network. The tutorial assumes manager1 has the IP address 192.168.99.100.
Step 2: Open Required Ports
Ensure the following ports are open between all your nodes:
- Port 2377 (TCP): For communication between manager nodes.
- Port 7946 (TCP/UDP): For node discovery within the overlay network.
- Port 4789 (UDP): For overlay network traffic (VXLAN).
If you plan to use an encrypted overlay network, ensure IPSec ESP traffic is allowed on IP protocol 50.
To secure your swarm further, consider applying the following iptables rule to block untrusted traffic from reaching the Swarm’s data path port (4789):
iptables -I INPUT -m udp --dport 4789 -m policy --dir in --pol none -j DROP
Step 3: Initializing the Swarm
Once your setup is ready, it’s time to initialize the Swarm on your manager node (manager1).
- SSH into the
manager1machine. - Run the following command to initialize the Swarm, specifying the IP address of the manager node:
docker swarm init --advertise-addr 192.168.99.100
If successful, the output will look like this:
Swarm initialized: current node (dxn1zf6l61qsb1josjja83ngz) is now a manager.It will also provide the command to add worker nodes to the swarm:
docker swarm join --token <worker-token> 192.168.99.100:2377
Step 4: Adding Worker Nodes to the Swarm
Now that the Swarm is initialized, you can add your worker nodes (worker1 and worker2).
- SSH into each worker node (
worker1andworker2). - Run the
docker swarm joincommand provided when you initialized the Swarm onmanager1.
For example, on worker1, the command might look like this:
docker swarm join --token SWMTKN-1-49nj1cmql0jkz5s954yi3oex3nedyz0fb0xx14ie39trti4wxv-8vxv8rssmk743ojnwacrr2e7c 192.168.99.100:2377Repeat this step for worker2. Once completed, both worker1 and worker2 will join the swarm and begin listening for tasks from the manager.
Step 5: Verifying the Swarm
To verify that all nodes have successfully joined the swarm, SSH into the manager node (manager1) and run the following command:
docker node lsYou should see all three nodes (manager1, worker1, and worker2) listed, along with their roles and statuses:
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
dxn1zf6l61qsb1josjja83ngz * manager1 Ready Active Leader
8l3nse6qox9pxdj67c5utodl4 worker1 Ready Active
fxp1kjvthh2qyuodhd83uixg5 worker2 Ready ActiveThe * next to manager1 indicates that you're currently connected to this node. The MANAGER STATUS column shows that manager1 is the leader.
Step 6: Deploying a Service to the Swarm
Now that your swarm is ready, you can deploy a service to it. For example, you can deploy an Nginx web server service with three replicas:
- SSH into the manager node (
manager1). - Run the following command to deploy the service:
This command creates a service calleddocker service create --name web --replicas 3 -p 8080:80 nginxwebwith three replicas, and each replica runs an Nginx container listening on port 80. The service is exposed to the outside world on port 8080.
Step 7: Managing the Swarm
After deploying a service, you can monitor and manage your swarm using several Docker commands.
Viewing Services
To see the list of services running in your swarm, use:
docker service lsViewing Nodes
To check the status of nodes in your swarm, use:
docker node lsScaling Services
If you want to scale the number of replicas for a service (e.g., increase Nginx replicas from 3 to 5), you can run:
docker service scale web=5Removing Services
To remove a service, use the following command:
docker service rm web
Conclusion
Docker Swarm Mode simplifies the process of managing containerized applications across multiple machines. By setting up a swarm and deploying services, you can build a scalable, fault-tolerant infrastructure with minimal effort. This tutorial has covered the essential steps to get started with Docker Swarm, from initializing the swarm to managing services on it.
Understanding Docker Swarm Mode Routing Mesh
Docker Swarm Mode introduces the concept of a routing mesh, a powerful feature that simplifies the process of exposing services to external clients in a swarm cluster. This tutorial provides an overview of how the ingress network and routing mesh work, how to publish ports for services, and how to configure an external load balancer like HAProxy to interact with a Swarm service.
What is the Routing Mesh?
The routing mesh in Docker Swarm Mode allows all nodes in the swarm to accept connections to a published service port, even if the service isn't running on that particular node. The routing mesh automatically routes incoming requests to a node where an instance of the service is active, ensuring the requests are handled efficiently and transparently.
Ingress Network
The ingress network is a special network created by Docker for the purpose of handling the routing mesh. All Swarm services are connected to the ingress network, allowing them to communicate and route requests to the correct node.
Key Ports to Open
Before you enable Swarm Mode and use the ingress network, make sure the following ports are open between the swarm nodes:
- Port 7946 (TCP/UDP): For container network discovery.
- Port 4789 (UDP): For the container ingress network (VXLAN).
How the Routing Mesh Works
When you publish a service in Docker Swarm, each node in the swarm can receive traffic for that service, regardless of whether the service is running on that node or not. The swarm manager's routing mesh ensures that requests are forwarded to the appropriate node where the service is active.
Example:
You have three nodes in your swarm:
node1with IP192.168.99.100node2with IP192.168.99.101node3with IP192.168.99.102
You deploy a service called my-web using the Nginx container. Even if the Nginx container is only running on node1 and node2, you can send a request to node3, and Docker will route that request to one of the active containers running on node1 or node2.
Here’s an example of the command to create the service with two replicas:
docker service create \
--name my-web \
--publish published=8080,target=80 \
--replicas 2 \
nginxIn this case, the Nginx service is available on port 8080 on all swarm nodes.
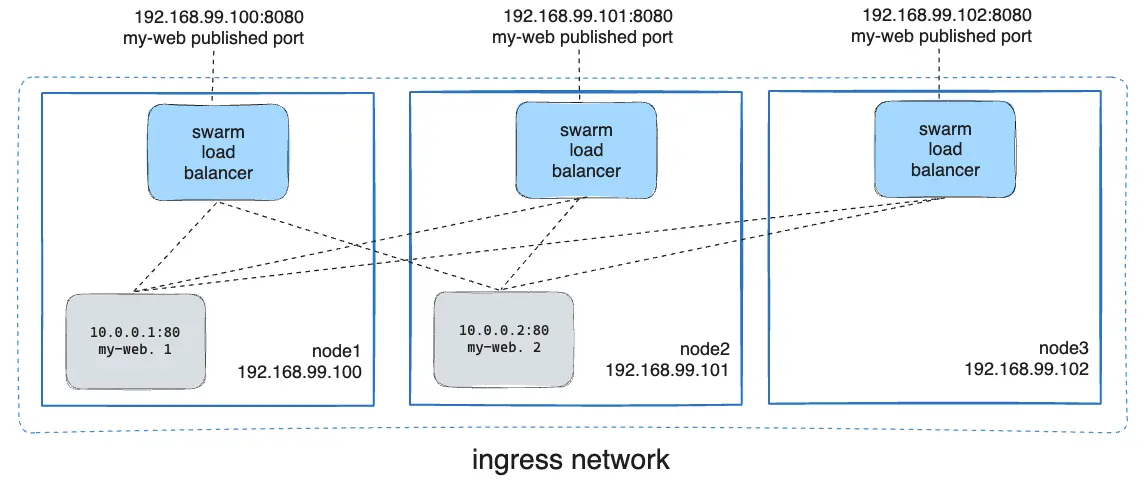
In the diagram above, you can see that requests sent to any node on port 8080 are routed to the appropriate Nginx instance.
Publishing a Port for a Service
To expose a service to the outside world, you use the --publish flag when creating the service. This flag lets you map a port on the node (published port) to a port inside the container (target port).
For example:
docker service create \
--name my-web \
--publish published=8080,target=80 \
nginxThis command publishes port 8080 on the swarm nodes and maps it to port 80 inside the Nginx container.
- published: The port that the swarm makes available outside the container.
- target: The port that the container listens on (inside the container).
Viewing Published Ports with docker service inspect
You can use docker service inspect to view detailed information about a service, including which ports have been published.
For example, to inspect the my-web service:
docker service inspect --format="{{json .Endpoint.Spec.Ports}}" my-webThe output will show the TargetPort (the container’s internal port) and the PublishedPort (the port on the swarm nodes):
[{"Protocol":"tcp","TargetPort":80,"PublishedPort":8080}]
Configuring an External Load Balancer with the Routing Mesh
In a real-world production scenario, you may want to use an external load balancer such as HAProxy to handle traffic across multiple swarm nodes. The load balancer can distribute incoming traffic to the nodes in the swarm, which will then use the routing mesh to route the traffic to the correct container.
Example HAProxy Configuration
The following HAProxy configuration listens on port 80 and forwards requests to the my-web service running on port 8080 on the swarm nodes:
global
log /dev/log local0
log /dev/log local1 notice
frontend http_front
bind *:80
stats uri /haproxy?stats
default_backend http_back
backend http_back
balance roundrobin
server node1 192.168.99.100:8080 check
server node2 192.168.99.101:8080 check
server node3 192.168.99.102:8080 checkThis configuration ensures that incoming traffic on port 80 is distributed across the nodes (node1, node2, and node3) on port 8080.
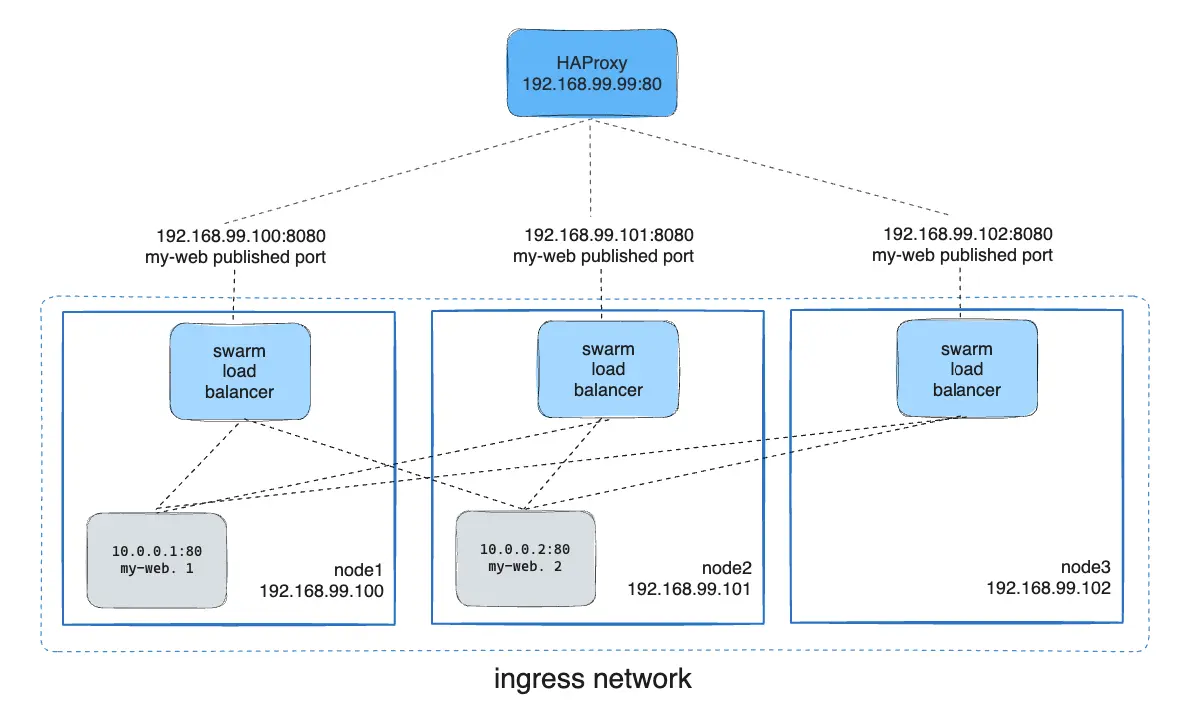
In the above diagram, the HAProxy load balancer distributes requests across all nodes in the swarm, and the swarm routing mesh ensures that traffic is forwarded to an active container.
Bypassing the Routing Mesh (Host Mode)
In some cases, you may want to bypass the routing mesh so that requests are sent directly to the node that is running the service. This is useful when you want to ensure that only nodes running the service are accessible on the published port. This mode is referred to as host mode.
To bypass the routing mesh, use the --publish flag with the mode=host option:
docker service create --name dns-cache \
--publish published=53,target=53,protocol=udp,mode=host \
--mode global \
dns-cacheIn host mode, traffic sent to a node will only be handled if that node is running the service task. Otherwise, the connection will fail.
Using an External Load Balancer Without the Routing Mesh
If you want to bypass the routing mesh entirely, you can configure an external load balancer to handle traffic without relying on the Swarm's built-in load balancing.
Use --endpoint-mode dnsrr to configure Docker to return a list of IP addresses for the nodes running the service when queried, rather than a virtual IP. This allows your external load balancer to directly handle traffic distribution based on DNS entries.
Example:
docker service create \
--name my-web \
--publish published=8080,target=80 \
--endpoint-mode dnsrr \
nginxIn this mode, the load balancer directly routes traffic to nodes running the service, without going through the swarm routing mesh.
Conclusion
Docker Swarm Mode's routing mesh and ingress network provide powerful and flexible ways to expose services to external clients. By using the routing mesh, all swarm nodes can participate in traffic routing, providing high availability and fault tolerance. For more control, you can configure external load balancers like HAProxy or bypass the routing mesh entirely to meet specific needs.
Whether you are using the default routing mesh or integrating with an external load balancer, Docker Swarm Mode simplifies the process of deploying and scaling services across distributed systems.